
Los problemas de JavaScript en buscadores LLM. Cómo solucionarlos
La problemática de JavaScript en buscadores LLM representa uno de los desafíos técnicos más significativos para el SEO actual. Mientras que los frameworks JavaScript han mejorado mucho la experiencia de usuario y las capacidades del desarrollo web, su adopción generalizada sin consideraciones de accesibilidad para crawlers puede generar barreras significativas para la visibilidad online.
La irrupción de los modelos de lenguaje de gran tamaño (LLM) como motores de búsqueda representa un cambio paradigmático en cómo los usuarios acceden a la información en interner. Plataformas como SearchGPT, Perplexity AI, Bing Chat o las Vistas de Ia de Google están redefiniendo las reglas del juego en el posicionamiento web y la visibilidad de las marcas en las respuestas de IA.
El problema es que estas nuevas tecnologías se enfrentan a desafíos técnicos importantes al interactuar con páginas web construidas con JavaScript.
Este artículo vamos a analizar en profundidad los problemas que presenta JavaScript para los crawlers basados en LLM, las diferencias con los motores de búsqueda tradicionales, y las estrategias que los profesionales del SEO pueden o deben implementar para garantizar la visibilidad de sus webs en esta nueva era de búsqueda asistida por inteligencia artificial.
JavaScript en el desarrollo web moderno
Sin duda, JavaScript es actualmente uno de los pilares fundamentales del desarrollo web contemporáneo. Frameworks y librerías como React, Vue.js, Angular, Next.js y Svelte dominan el panorama tecnológico, permitiendo crear webs que garantizan experiencias de usuario ricas, interactivas y dinámicas.
Según diversas estadísticas, más del 70% de las páginas web utilizan JavaScript de forma sustancial, y frameworks como React impulsan millones de aplicaciones web en producción.
Sin embargo, como vamos a ver a continuación, los crawlers de LLM tienen pocas capacidades de ejecución de JavaScript
Cómo funcionan los crawlers de LLM
Los crawlers de buscadores basados en LLM operan de manera fundamentalmente diferente a los motores de búsqueda tradicionales:
- Extracción de contenido: Recuperan el contenido de las páginas web
- Procesamiento mediante LLM: Analizan y comprenden el contenido usando modelos de lenguaje
- Generación de respuestas: Sintetizan información para responder consultas de usuarios
- Citación de fuentes: Referencian las páginas originales en sus respuestas
A diferencia de Google, que indexa y rankea páginas, los LLM buscan extraer información comprensible y relevante para generar respuestas coherentes y contextualizadas.
Cuando los LLMs hacen scraping de páginas web a través de sus herramientas integradas: como web_fetch en Claude, web tool en ChatGPT…, normalmente no ejecutan JavaScript. Es una petición HTTP simple que descarga el HTML estático del servidor. Esto significa que:
- No se ejecutan scripts de JavaScript
- No se renderizan estilos CSS
- No hay contexto visual/renderizado
- Solo se obtiene el HTML crudo del servidor
Diferencias con Google y otros motores tradicionales
Google ha invertido años en desarrollar capacidades sofisticadas de renderización de JavaScript:
- Googlebot renderiza JavaScript: Ejecuta código JS en un navegador headless (Chromium)
- Proceso en dos fases: Primero crawlea el HTML, luego renderiza JS en una cola secundaria
- Recursos limitados: Aunque puede renderizar, tiene límites de tiempo y recursos
- Retrasos en indexación: El contenido JavaScript puede tardar más en indexarse
Los crawlers LLM actuales generalmente no disponen de estas capacidades avanzadas, operando más como los crawlers tradicionales de hace una década. Esto representa un retroceso importante en términos de compatibilidad con arquitecturas web modernas. y que pueden afectar directamente a su visibilidad en los buscadores impulsados por IA generativa.
Ver Crawling. Qué es y Cómo afecta al SEO en 2025
Los LLM no ejecutan JavaScript
La mayoría de los crawlers LLM actuales operan de forma similar a navegadores sin capacidad de ejecución de JavaScript, o con capacidades muy limitadas. Esto significa que:
- No ejecutan JavaScript: Reciben únicamente el HTML inicial del servidor
- No esperan renderización: No esperan a que frameworks como React «hidraten» el contenido
- No interactúan con APIs: No realizan las llamadas asíncronas que cargan contenido dinámico
- No procesan estados: No acceden a contenido que depende de interacciones del usuario

Problemas específicos de JavaScript para Crawlers LLM
1. Contenido Invisible para el Crawler
El problema más grave ocurre cuando el contenido principal de una página se genera completamente mediante JavaScript:

Para un crawler LLM, la página aparece prácticamente vacía, aunque para el usuario muestre información original y valiosa.
2. Carga Asíncrona de Datos
Las aplicaciones modernas frecuentemente cargan datos mediante llamadas API después del montaje inicial:

Este patrón, muy común en aplicaciones React o Vue, resulta completamente invisible para crawlers que no ejecutan JavaScript.
3. Enrutamiento del Lado del Cliente (CSR)
Las SPAs utilizan enrutamiento del lado del cliente (React Router, Vue Router, etc.), donde las transiciones entre «páginas» no generan peticiones HTTP reales.
Los crawlers LLM pueden no entender correctamente la estructura de navegación de estos sitios.
4. Contenido Condicional y Lazy Loading
Técnicas de optimización como Lazy Loading, Code Splitting, y renderización condicional pueden ocultar contenido importante:

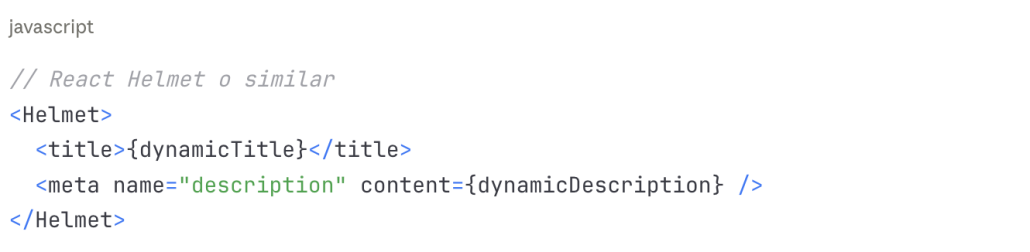
5. Metadatos dinámicos
Los metadatos SEO gestionados dinámicamente (títulos, descripciones, Open Graph tags) mediante JavaScript pueden no ser reconocidos:
Implicaciones de los problemas de renderizado para el SEO
Posible pérdida de visibilidad en respuestas LLM
Si el contenido de tu sitio no es accesible para crawlers LLM, simplemente no aparecerá en las respuestas generadas por estos sistemas. Esto significa:
- Cero menciones: Tu marca no será citada como fuente
- Pérdida de tráfico: Los usuarios no llegarán a tu sitio
- Desventaja competitiva: Competidores con mejor implementación técnica ganarán visibilidad
Los profesionales SEO ahora debemos optimizar para múltiples tipos de crawlers con capacidades radicalmente diferentes:
- Google (renderiza JS): Continúa siendo el líder con capacidades avanzadas
- Crawlers LLM (limitados con JS): Requieren enfoques más tradicionales
- Redes sociales: Necesitan metadatos específicos y a menudo no ejecutan JS
- Otros buscadores: Capacidades variables (Bing, Yandex, etc.)
La optimización para este ecosistema diverso aumenta significativamente la complejidad técnica del SEO moderno y requiere conocimientos más profundos de desarrollo web.
Evolución de los crawlers LLM
Es muy probable que los crawlers LLM evolucionen en los próximos años y permitan:
- Mejor ejecución de JavaScript: Inversión en capacidades de renderización
- Crawling selectivo inteligente: Priorizar contenido basándose en señales de calidad
- Protocolos específicos: Posibles estándares para facilitar el acceso a contenido dinámico
- APIs para desarrolladores: Interfaces para facilitar la indexación de contenido complejo
Mientras tanto, la mayoría de expertos recomiendan el uso de:
- Arquitecturas flexibles: Diseños que puedan adaptarse a cambios
- Separación de contenido y presentación: Content APIs independientes
- Adopción de estándares: Structured data, semantic HTML
- Monitorización continua: Adaptación basada en cambios del ecosistema
Soluciones para mejorar la ejecución de JavaScript en crawlers LLM
El SEO en aplicaciones construidas con JavaScript puede ser un desafío, sobretodo cuando se usa Client-Side Rendering (CSR), ya que los motores de búsqueda tradicionales y LLM pueden tener dificultades para indexar contenido generado dinámicamente.
En el Client-Side Rendering (CSR), el contenido de la página se genera completamente en el navegador del usuario mediante JavaScript. Al acceder a una URL, el servidor envía un archivo HTML vacío o con un contenido mínimo, y el navegador descarga, ejecuta y renderiza el JavaScript necesario para mostrar la página.
Por tanto, para la facilitar la ejecución del JavaScript en los motores de búsqueda debemos renderizar el contenido en el servidor. Y para ello disponemos de diversas formas de hacerlo, con sus ventajas y desventajas, que vamos a analizar ahora:
1. Server-Side Rendering (SSR)
El SSR representa la solución más robusta al renderizar el contenido en el servidor antes de enviarlo al cliente:
Frameworks que lo soportan:
- Next.js (React)
- Nuxt.js (Vue)
- SvelteKit (Svelte)
- Angular Universal (Angular)
Ventajas:
- Contenido completamente accesible para cualquier crawler
- Mejor rendimiento inicial (First Contentful Paint)
- SEO optimizado por diseño
- Compatible con crawlers LLM sin configuración adicional
Consideraciones:
- Mayor complejidad en el servidor
- Costes de infraestructura potencialmente superiores
- Requiere repensar arquitecturas CSR existentes
2. Static Site Generation (SSG)
La generación estática pre-renderiza páginas en tiempo de compilación:
Herramientas destacadas:
- Next.js (Static Export)
- Gatsby
- Hugo
- Eleventy
Ventajas:
- Máximo rendimiento (archivos estáticos)
- Perfecto para crawlers LLM
- Hosting económico
- Excelente seguridad
Limitaciones:
- Menos adecuado para contenido altamente dinámico
- Requiere regeneración para actualizar contenido
- No apropiado para aplicaciones con mucha interactividad en tiempo real
3. Renderización Híbrida (ISR – Incremental Static Regeneration)
Next.js popularizó este enfoque que combina SSG con revalidación bajo demanda:

Beneficios:
- Combina velocidad de contenido estático con frescura de contenido dinámico
- Escalable para sitios grandes
- Excelente para crawlers LLM
4. Pre-rendering para Crawlers
Implementar servicios que detectan crawlers y sirven versiones pre-renderizadas:

Soluciones disponibles:
- Prerender.io
- Rendertron (Google)
- Puppeteer/Playwright (soluciones custom)
Consideraciones importantes:
- Google desaconseja el cloaking agresivo
- Debe servirse el mismo contenido, solo pre-procesado
- Mantener sincronización entre versiones
5. Progressive Enhancement
Adoptar un enfoque de mejora progresiva donde el contenido básico existe sin JavaScript:

6. Metadatos Estáticos
Asegurar que metadatos críticos estén en el HTML inicial:

7. Structured Data Estático
Implementar datos estructurados directamente en el HTML:

Mejores Prácticas para Sitios JavaScript
A pertir de estos datos, podemos implementar una serie de medidas para asegurar la máxima compatibilidad de JavaScript con todos los motores de búsqueda
- Auditar contenido crítico: Identificar qué contenido debe ser accesible sin JS
- Implementar SSR/SSG: Para contenido público importante
- Optimizar metadatos: Asegurar que estén en HTML inicial
- Structured data estático: No depender de JS para schema markup
- Texto alternativo: Imágenes con alt text en HTML, no añadido por JS
- Enlaces navegables: Usar elementos <a> reales, no divs con onClick
- Contenido principal visible: El contenido clave debe estar en el HTML inicial
- Testear sin JavaScript: Verificar regularmente qué ven los crawlers básicos
Arquitectura Recomendada para Nuevos Proyectos
Para proyectos que priorizan SEO y visibilidad en LLMs:
- Next.js o Nuxt.js como framework base
- SSG para páginas estáticas (landing, blog, recursos)
- SSR para páginas dinámicas pero públicas
- CSR solo para áreas autenticadas o aplicaciones web
- API Routes para funcionalidad dinámica
- CDN global para distribución optimizada
Migración de Sitios CSR Existentes
Para sitios ya construidos con CSR y quieren introducir mejoras SEO que favorecen la ejecución de JavaScript en los motores de búsqueda tradicionales y LLM.
Fase 1 – Evaluación:
- Auditar qué contenido es crítico para SEO
- Identificar páginas con mayor impacto en tráfico
- Evaluar esfuerzo técnico de migración
Fase 2 – Implementación Progresiva:
- Comenzar con páginas de mayor valor (home, páginas de producto/servicio)
- Implementar SSR/SSG gradualmente
- Mantener monitorización de rendimiento
Fase 3 – Optimización:
- Refinar implementación basándose en métricas
- Expandir a más páginas
- Mantener áreas interactivas en CSR cuando sea apropiado
Análisis de Frameworks JavaScript populares y sus problemáticas
React: El gigante con importantes desafíos SEO
React, siendo el framework más popular del mercado, presenta desafíos significativos en su implementación más común (Create React App – CRA):
- Renderización exclusivamente en cliente: El HTML inicial contiene únicamente un div vacío (<div id=»root»></div>)
- Bundle size considerable: Los archivos JavaScript pueden ser pesados, aumentando el tiempo de carga
- Dependencia total de JavaScript: Sin JS, la página aparece completamente en blanco
- Hidratación diferida: El contenido aparece solo después de descargar y ejecutar todo el bundle
Ejemplo del problema:
Soluciones específicas para React:
Migrar a Next.js: La solución más recomendada

React Server Components: Tecnología emergente de React 18+
- Componentes que se ejecutan exclusivamente en servidor
- Reducen el JavaScript enviado al cliente
- Mejor compatibilidad con crawlers
Prerender específico: Usar react-snap o react-snapshot

React Helmet Async: Para metadatos dinámicos con SSR

Vue.js: Flexible, pero requiere Configuración
Vue, aunque más orientado a SEO que React, presenta desafíos similares:
- Vue CLI por defecto usa CSR: Mismo problema del div vacío
- Vue Router en modo hash: Las rutas con # no son ideales para SEO
- Componentes asíncronos: Pueden causar contenido invisible para crawlers
- Vuex state inicial: El estado de la aplicación no está disponible sin ejecutar JS
Soluciones específicas para Vue:
Migrar a Nuxt.js: Framework SSR/SSG para Vue

• Vue SSR Manual: Implementación propia del servidor

Vue Router en modo history: Evitar rutas hash
• Prerender SPA Plugin: Para sitios principalmente estáticos
Angular: Enterprise pero Complejo
Problemática principal:
Angular, siendo un framework completo, tiene sus propios desafíos:
- Bundle inicial muy pesado: Puede superar 1MB fácilmente
- Tiempo de arranque considerable: TTI (Time to Interactive) elevado
- Compilación compleja: Requiere entender Ahead-of-Time compilation
- Dependencias del framework: Todo el ecosistema Angular debe cargarse
Soluciones específicas para Angular:
• Angular Universal: SSR oficial de Angular

• Angular Prerendering: Para sitios estáticos

• Lazy Loading optimizado: Reducir bundle inicial
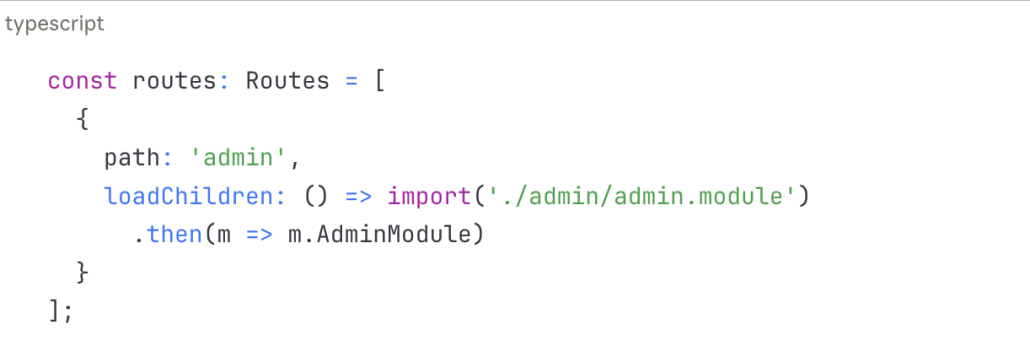
• TransferState: Evitar peticiones duplicadas

Next.js: Solución para React
Ventajas inherentes:
Next.js fue diseñado específicamente para resolver problemas de SEO en React:
- SSR por defecto: Contenido accesible desde el primer render
- SSG integrado: Pre-generación de páginas estáticas
- ISR (Incremental Static Regeneration): Lo mejor de ambos mundos
- Automatic Code Splitting: Optimización automática de bundles
- Image Optimization: Componente Image optimizado para SEO
Principales problemas de Next.js
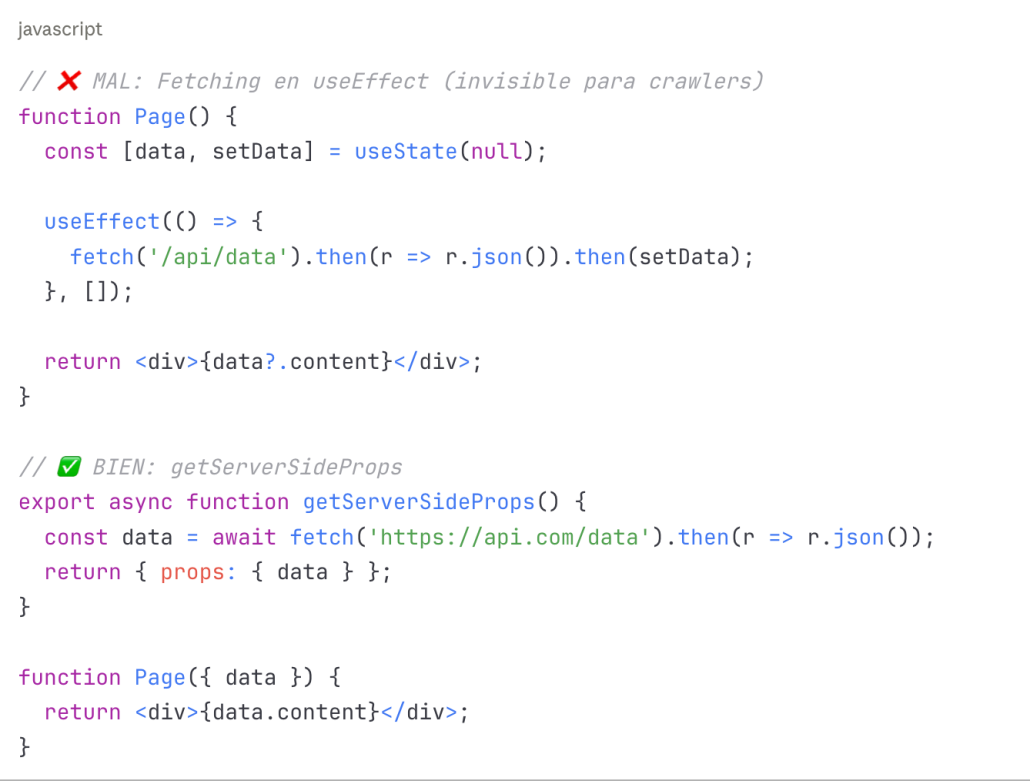
• Usar getStaticProps para contenido estático:

• Metadata API de Next.js 13+:

• Optimización de imágenes:

Nuxt.js: La solución para Vue
Ventajas similares a Next.js:
Nuxt.js es para Vue lo que Next.js es para React:
- SSR/SSG integrado: Múltiples modos de renderización
- File-based routing: Estructura clara y SEO-friendly
- Auto-imports: Mejor developer experience
- Módulos ecosystem: Extensible con módulos oficiales

Meta tags dinámicos en Nuxt 3:

Svelte/SvelteKit: El competidor eficiente
Svelte compila a JavaScript vanilla, resultando en bundles más pequeños:
- Sin runtime: El código se compila a JS puro
- Bundles ligeros: Menos código para descargar y ejecutar
- Performance superior: Arranque más rápido
- Simplicidad: Curva de aprendizaje menor
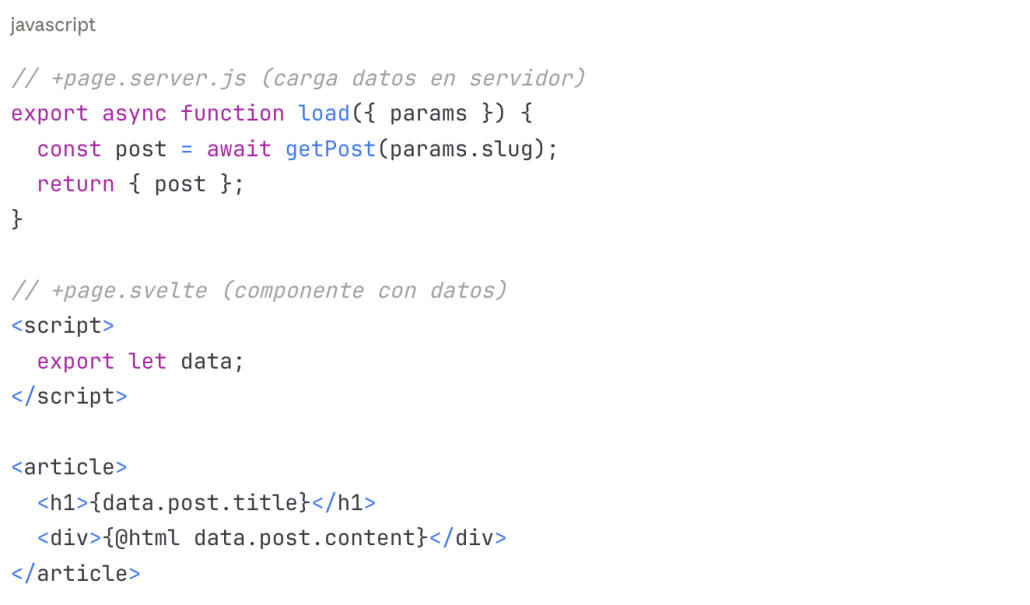
Pre-renderización en SvelteKit:

Comparativa de soluciones por Framework
| Framework | Problema Principal | Solución Recomendada | Dificultad Implementación | Rendimiento SEO |
| React (CRA) | CSR completo | Migrar a Next.js | Media | ⭐⭐⭐⭐⭐ |
| Vue (CLI) | CSR completo | Migrar a Nuxt.js | Media | ⭐⭐⭐⭐⭐ |
| Angular | Bundle pesado | Angular Universal | Alta | ⭐⭐⭐⭐ |
| Next.js | (Mal uso de useEffect) | getServerSideProps/getStaticProps | Baja | ⭐⭐⭐⭐⭐ |
| Nuxt.js | (Mala configuración) | Configurar SSR correctamente | Baja | ⭐⭐⭐⭐⭐ |
| SvelteKit | Pocos casos problemáticos | SSR por defecto | Baja | ⭐⭐⭐⭐⭐ |
La problemática de JavaScript en buscadores LLM representa uno de los desafíos técnicos más significativos para el SEO hoy.
Mientras que los frameworks JavaScript han mejorado dramáticamente la experiencia de usuario y las capacidades del desarrollo web, su adopción generalizada sin consideraciones de accesibilidad para crawlers crea barreras significativas para la visibilidad online.
Las empresas que deseen mantener relevancia en el ecosistema de búsqueda asistida por IA deben:
- Auditar rigurosamente su stack tecnológico actual
- Implementar estrategias de renderización apropiadas (SSR/SSG)
- Adoptar enfoques híbridos que balanceen UX y accesibilidad
- Monitorizar continuamente el rendimiento en diversos crawlers
- Mantenerse informados sobre la evolución del ecosistema
La clave del éxito radica en encontrar el equilibrio óptimo entre experiencias de usuario ricas e interactivas y la accesibilidad del contenido para sistemas automatizados cada vez más diversos. Las organizaciones que logren este equilibrio estarán mejor posicionadas no solo para los motores de búsqueda LLM actuales, sino para el futuro incierto de la búsqueda y el descubrimiento de información en línea.
En SeoinHouse.es, como agencia SEO, continuamos monitorizando estas tendencias y desarrollando estrategias adaptativas que garanticen la visibilidad de nuestros clientes en todos los canales relevantes, desde motores de búsqueda tradicionales hasta plataformas emergentes basadas en inteligencia artificial.
También puedes en nuestro blog:
SEO JavaScript. Qué es y cómo afecta al posicionamiento de una web
Optimización de Motores Generativos (GEO): La Nueva Era del SEO en 2025
La revolución de los buscadores con IA en 2025: cómo adaptarte y optimizar tu SEO
SEO para IA: Optimización para Inteligencia Artificial Generativa(AIO). Guía completa