
Por qué deberías dejar rastrear tu web por los boots de IA
Los bots de IA como GPTBot rastrean sitios web para recopilar información. La principal diferencia es que, en lugar de que una plataforma de IA reciba datos de forma pasiva para aprender de ellos (el «conjunto de entrenamiento», por así decirlo), un bot puede buscar información activamente en la web rastreando varias páginas.
Los LLM, como GPT, Claude, Perplexity… cambian el modo en que los motores de búsqueda y los asistentes de IA procesan y responden a las consultas, yendo más allá de la simple coincidencia de texto para ofrecer respuestas matizadas y contextualmente ricas.
Ver La revolución de los buscadores con IA en 2025: cómo adaptarte y optimizar tu SEO
Los LLM demuestran capacidades notables en comprensión y razonamiento del lenguaje que van más allá de la simple correspondencia de texto para proporcionar respuestas más matizadas y contextuales, según investigaciones como “Large Search Model: Redefining Search Stack in the Era of LLMs” de Microsoft.
Al utilizar PNL, la ventana de contexto se puede ampliar para tener en cuenta la estructura gramatical de las oraciones, lo que permite la identificación de entidades principales y secundarias durante la comprensión del lenguaje natural.
La IA generativa se extiende más allá del texto para incluir formatos multimedia como audio y, ocasionalmente, elementos visuales.
Ver LLMO. Incorpora tu marca a las respuestas de IA
Según un estudio realizado por Ahref con 3.000 páginas web, el 63% de ellas han recibido trafíco procedente de varios chat bots de IA, sobretodo Chat GPT ( el 50%).
Según otro estudio publicado por Press Gazzette, las visitas totales a la web desde computadoras de escritorio y dispositivos móviles referidas a 14 editores líderes a nivel mundial por ChatGPT, propiedad de OpenAI, aumentaron ocho veces, de 435.000 en agosto a 3,5 millones en enero.
Sin embargo, ese mismo grupo de sitios recibió un total de 3.800 millones de visitas en enero, lo que significa que el tráfico de ChatGPT representó menos del 0,1% de todas las visitas.
Cada plataforma utiliza sus propios procesos. No habrá una sola optimización
La funcionalidad principal de los LLM en la búsqueda es procesar consultas y producir resúmenes en lenguaje natural.
En lugar de simplemente extraer información de documentos existentes, estos modelos pueden generar respuestas integrales manteniendo la precisión y la relevancia.
Ver El modo IA de Google cambia el 91 % en las URL en búsquedas repetidas
Esto se logra mediante un marco unificado que trata todas las tareas (relacionadas con la búsqueda) como problemas de generación de texto.
Lo que hace que este enfoque sea particularmente poderoso es su capacidad de personalizar las respuestas mediante indicaciones en lenguaje natural. El sistema primero genera un conjunto inicial de resultados de consulta, que el LLM refina y mejora.
Los diferentes resultados de las aplicaciones de IA demuestran que cada plataforma utiliza sus propios procesos y criterios para recomendar entidades designadas y seleccionar fuentes.
En el futuro, probablemente será necesario trabajar con múltiples modelos de lenguaje o asistentes de IA de gran tamaño y comprender sus funcionalidades únicas. Para los especialistas en SEO acostumbrados al dominio de Google, esto requerirá un ajuste.
Ver SEO de entidades: Cómo estructurar el contenido en la era de la IA
En los próximos años, será esencial monitorear qué aplicaciones ganan terreno en mercados e industrias específicos y comprender cómo cada uno selecciona sus fuentes.
Mas info en este artículo sobre como hacerse visible en los buscadores IA
Ver Cómo sobrevivir en un mundo de búsquedas generadas por IA, con menos clics
3 razones para no bloquear GPTBot de ChatGPT
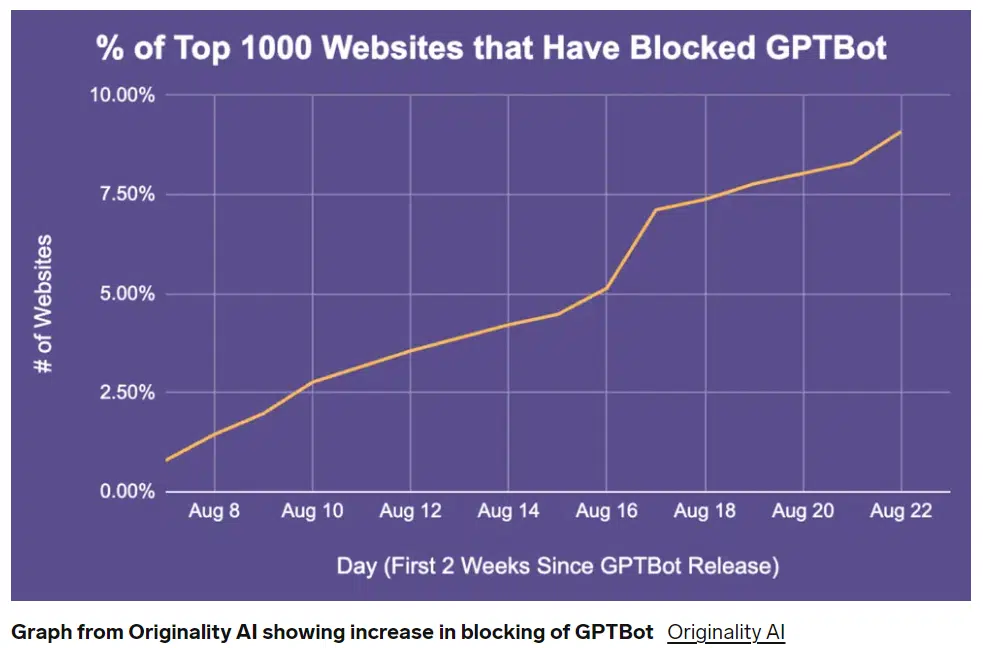
Muchas marcas impiden que GPTBot rastree su sitio porque no quieren que sus datos se utilicen para entrenar sus modelos sin compensación.
ChatGPT, al igual que Google y YouTube, es un motor de respuestas para todo el mundo. Evitar que GPTBot rastree tu contenido podría limitar el alcance de tu marca a un grupo más pequeño de usuarios de Internet en el futuro.
Entonces, ¿por qué debería permitir que GPTBot rastree su sitio? Veamos el lado positivo de estos tres beneficios principales de adoptar la tecnología de bots de OpenAI.
1º Al no permitir que GPTBot y de otros LLM rastreen tu sitio, estás perdiendo una audiencia de 100 millones de personas que no podrá maximizar la visibilidad de su marca.
Compartir el acceso al contenido de su sitio web puede ayudar a garantizar que su marca esté representada de manera objetiva y positiva ante los usuarios de ChatGPT.
Esto significa que hay una mayor probabilidad de que ChatGPT recomiende su marca, lo que genera más tráfico y clientes potenciales.
2º Independientemente de si le teme a la IA, todos podemos estar de acuerdo en que está cambiando el panorama del marketing. Como sucede con todas las nuevas tecnologías y tendencias de nuestro sector, quienes se muestren lentos a la hora de adoptar la IA como un canal para generar nuevos negocios y exposición de marca se perderán el barco proverbial.
3º Una desconfianza sana hacia las tecnologías de inteligencia artificial es importante para su crecimiento legal y ético, pero también debemos tener la mente abierta y darnos cuenta de que no podemos ser eficaces como vendedores si nos resistimos y elegimos no crecer ni innovar en la dirección correcta.
A medida que la tecnología de inteligencia artificial avanza, es fácil dejarse llevar por el escepticismo, el miedo y el ruido. Aquellos que tengan dificultades para adoptarla y aprovecharla al máximo se quedarán atrás.
Principales rastreadores de IA
Al configurar su archivo robots.txt, tenga en cuenta estos principales rastreadores de IA:
- OpenAI
- GPTBot
- ChatGPT-User
- OAI-SearchBot
- Google
- Google-Extended
- GoogleOther
- Anthropic: ClaudeBot
- Andi: AndiBot.
- Perplexity: PerplexityBot.
- You.com: YouBot.
- Phind: PhindBot.
- Exa: ExaBot.
- Firecrawl: FirecrawlAgent.
- Common Crawl: CCBot
Más boots de IA aquí
Ojo según Search Engine Land, los rastreadores de IA están lejos de ser perfectos. En este momento:
- El 34% de las solicitudes de rastreadores de IA dan errores 404 u otros.
- Actualmente, entre los principales rastreadores de IA, solo Gemini y AppleBot de Google procesan JavaScript.
- Los rastreadores de IA muestran una ineficiencia 47 veces mayor en comparación con los rastreadores tradicionales como Googlebot.
- Los rastreadores de IA representan aproximadamente el 28% del volumen de Googlebot en el análisis de tráfico reciente.
- ChatGPT y Copilot tienen sus propios algoritmos de clasificación, pero extraen información del índice de Bing cuando observan los resultados.
- Perplexity trabaja con terceros para crear activamente su propio índice . Por lo tanto, no nos basamos en el análisis de la estrategia de contenido de Google.
Aun así, está calro que mantenerse al día de estas tendencias te ayudará a garantizar que tu contenido siga siendo visible.
Configura tu archivo robots.txt para rastreadores de IA
Agrega un archivo robots.txt con acceso a la búsqueda de agentes de IA, pero no permita la recopilación de datos de entrenamiento tipo:
# Allow AI search and agent use User-agent: OAI-SearchBot User-agent: ChatGPT-User User-agent: PerplexityBot User-agent: FirecrawlAgent User-agent: AndiBot User-agent: ExaBot User-agent: PhindBot User-agent: YouBot Allow: /# Disallow AI training data collection User-agent: GPTBot User-agent: CCBot User-agent: Google-Extended Disallow: /# Allow traditional search indexing User-agent: Googlebot User-agent: Bingbot Allow: /# Disallow access to admin areas for all bots User-agent: * Disallow: /admin/ Disallow: /internal/Sitemap:Más información sobre la importancia del archivo robots.txt y como configurarlo según Google
Según parece, bloquear los boots de IA es un error que puede costarte un incremento de tráfico importante o dicho de otra forma más comercial, no estar ante los ojos de clientes potenciales que confían en estas platafomas de IA para obtener información ( parece que cada vez son más), además de olvidarte un poco de la servidumbre al modelo tradicional de optimización para Google.
Según Statcounter, la participación de Google en el mercado mundial de motores de búsqueda cayó por debajo del 90 % por primera vez desde 2015 durante cada uno de los últimos tres meses de 2024, sobre todo en Asia. Aun así, como hemos visto al principio, este tráfico se ha repartido básicamente entre otros buscadores tradicionañes, con Bing a la cabeza . Más info
Para mí, incluir boots de IA generativa en nuestro robots.txt lo veo como una oportunidad, las plataformas de IA siguen creciendo y Google está avanzando en este mismo camino. Su IA seguramente tarde o temprano modificará los resultados de búsqueda, con lo que si piensas en optimizar para otros buscadores de IA posiblemente también lo estés haciendo para Google.
¿Debería crear un archivo llms.txt en mi web?
El archivo llms.txt es un archivo de texto diseñado para indicar a los LLM dónde encontrar la información útil. Un estándar propuesto para ayudar a los LLM a acceder e interpretar contenido estructurado de sitios web. Más info en llmstext.org
En teoría, esto parece una buena idea. Igual que usamos archivos como robots.txt y sitemap.xml para ayudar a los motores de búsqueda a comprender el contenido de un sitio, podemos usar un archivo para indicarle a los LLM dónde buscar y encontrar la información útil en nuestra web.
El problema es que ningún proveedor importante de LLM admite actualmente llms.txt. Ni OpenAI, ni Anthropic, ni Google.
En esencia, un archivo llms.txt es un documento Markdown (un tipo de archivo de texto con un formato especial) que utiliza encabezados H2 para organizar los enlaces a recursos clave y debe colgar de dominio raíz: https://yourdomain.com/llms.txt
Aquí puedes ver un ejemplo
John Mueller de Google minimiza su utilidad y lo compara a la metaetiqueta de palabras clave, ya en desuso.
Si aún así, crees que es interesante tenerlo en tu web puedes crear tu archivo llms.txt aquí
También pudes leer:
La importancia del Social Branding para diferenciar y potenciar tu marca
Cómo actuará Google frente a IA. Mejora tu EEAT, por si acaso.
Del SEO centrado en Keywords al SEO orientado a temas
SEO para IA. 17 Estrategias para que tu contenido sea seleccionado por los LLM
Por qué el SEO tradicional ya no es suficiente en la era de la IA
Enlaces Internos en SEO: de la transmisión de Autoridad a los Mapas de Entidades