Crawling. Qué es y cómo afecta al SEO en 2026
Actualizada el 28 de enero de 2026
Qué es crawling
El crawling o rastreo es el proceso mediante el que los motores de búsqueda, como Google, descubren, analizan y acceden al contenido de una web para indexarlo. Su impacto en el SEO es muy importante: si no hay un buen rastreo, las páginas no aparecen en los resultados de búsqueda (SERP), lo que hace al sitio invisible, afectando directamente su posicionamiento
La palabra ‘crawling‘ o ‘crawleo‘ proviene de la palabra ‘crawler’, que es como suele llamarse a los robots de búsqueda (arañas, spiders, boots, son otras denominaciones) e indica el recorrido que hace un pequeño bot de software (un crawler) para leer y analizar el código y contenido de una web, saltando de página en página a través de los enlaces que va encontrando.
En el caso del GoogleBot (el crawler de Google), este se encarga de rastrear y examinar nuestras webs, para posteriormente incorporarlas a su índice. para clasificar e indexar todas y cada una de las páginas web existentes en la red.
Estos son algunos de los boots de Google
La indexación es fundamental para la visibilidad y el posicionamiento orgánico (SEO) de nuestra página, ya que es lo que va a determinar qué lugar ocupará en la página de resultados tras las búsquedas de los usuarios.
Los crawlers enviados por Google (el resto de buscadores utilizan herramientas similares) tienen una hoja de ruta muy clara:
- Encontrar todas las páginas web existentes.
- Analizarlas en función de una fórmula o algoritmo.
- Asignarles a cada una de ellas una posición determinada en la SERP.
Hablamos de crawlers en plural y no de crawler en singular porque existen distintos tipos de rastreadores y cada uno de ellos se encarga de analizar y puntuar una información diferente. Uno de ellos es el crawl budget, el cual asigna un tiempo específico a cada link, y que analizaremos con detalle en este artículo un poco más adelante.
Tipos de Crawlers y sus Funciones
Existen varios tipos de crawlers, cada uno con un propósito específico:
- Googlebot: El principal crawler de Google que se encarga de rastrear e indexar páginas web.
- Image Crawlers: Especializados en rastrear contenido multimedia como imágenes.
- Video Crawlers: Enfocados en contenido de video.
- Mobile Crawlers: Optimizados para rastrear y analizar sitios web móviles.
Estos son algunos de los boots de Google https://developers.google.com/search/docs/crawling-indexing/overview-google-crawlers?hl=es&visit_id=638562931069087229-928615095&rd=1
A pesar de la existencia de más de 30 motores de búsqueda web importantes , la comunidad SEO realmente solo presta atención a Google. ¿Por qué? La respuesta corta es que Google es donde la gran mayoría de la gente busca en la web. Si incluimos Google Images, Google Maps y YouTube (una propiedad de Google), más del 90% de las búsquedas web se realizan en Google, es decir, casi 20 veces más que Bing y Yahoo juntos.
Importancia del Crawling en el SEO de una página web
El crawling es esencial porque permite:
- Visibilidad: Sin el crawling, una página web no puede ser indexada y, por lo tanto, no aparecerá en los resultados de búsqueda.
- Posicionamiento: La calidad y la accesibilidad del contenido evaluado durante el crawling afectan la clasificación de la página en la SERP.
- Actualización: Los bots de búsqueda rastrean regularmente las páginas web para identificar actualizaciones y cambios, lo que asegura que el contenido más reciente esté disponible en los resultados de búsqueda
¿Cómo Funciona el Crawling?
Con hemos visto anteriormente el proceso de crawling de una página web o tienda online implica varios pasos clave:
- Descubrimiento de Páginas: Los crawlers comienzan su recorrido desde una lista de URLs conocidas y luego siguen los enlaces presentes en esas páginas para descubrir nuevas URLs.
- Análisis del Contenido: Los bots examinan el contenido y el código HTML de cada página, evaluando elementos como títulos, metadatos, texto, imágenes y enlaces.
- Indexación: Una vez analizadas, las páginas se indexan en la base de datos del motor de búsqueda, lo que permite su recuperación cuando los usuarios realizan consultas relacionadas.
No debemos asumir que si Google ha rastreado una URL, automáticamente la va a indexar. La realidad es bastante más compleja: Google puede decidir no indexar una URL por diversas razones, incluso cuando la rastrea constantemente.
- Baja calidad del contenido
- Poca autoridad de dominio
- Problemas de duplicidad
- Mala experiencia en la página
- Poca credibilidad de la web, el autor o el contenido
Además, aunque una URL puede haber sido indexada en algún momento nada garantiza que continúe estándolo en el futuro.
En el extremo opuesto, Google puede indexar una URL que no ha rastreado nunca. Por ejemplo, cuando una URL está bloqueada por un archivo robots.txt que le prohíbe visitarla, pero Google encuentra enlaces hacia esa URL, podría indexarla sin realizar un rastreo.

¿Cómo realiza Google el crawling de las webs?
En primer lugar, Google debe conocer de la existencia de nuestra web y de su disponibilidad para que los distintos boots realicen el proceso de rastreo e indexación de la misma. Para ello, contamos con diferentes opciones, siendo las más habituales la creación de enlaces externos hacia el sitio web en cuestión o el alta en la plataforma Search Console, envio de un sitemap, entre otras.
Pasado este punto, los crawlers de Google empezará el proceso de rastreo de la página web, accediendo a todas las páginas a través de los distintos enlaces internos que hayamos creado. También puede beber de otras fuentes para encontrar una página o sección de nuestra web, como su existencia en un archivo Sitemap que hayamos dado de alta en Search Console.
Además de los componentes mencionados, la colaboración entre el rastreo, indexación y ranking es vital para establecer la relevancia de los resultados de búsqueda.
Un buen funcionamiento de rastreo garantiza que las páginas actuales y valiosas sean reconocidas por los motores de búsqueda, estableciendo las bases para una indexación efectiva.
Posteriormente, con un contenido bien indexado, los algoritmos de clasificación pueden evaluar de manera precisa y rápida qué páginas son más pertinentes para las consultas de los usuarios, asegurando así una mayor visibilidad y alcance.
En este interesante podcats de Search Off de Record de Google, John Mueller, Lizzi Sassman y Gary Illyes hablan sobre los conceptos erróneos en torno a la frecuencia de rastreo y la calidad del sitio, lo que es un reto en el rastreo de una web hoy en día, y cómo los motores de búsqueda podrían rastrear de manera más eficiente.
Fases del proceso de rastreo de una web:
El crawling se compone de 3 fases principales, que son:
1º Crawling o rastreo
El objetivo del bot es conocer qué hay en la web. Esta primera fase es en la que los bots entran en cada página de la web y va “leyendo” qué es lo que hay en ella.
Si a esto añadimos un buen interlinking ( enlazado interno), los bots se van a mover como peces en el agua por la web. Así, vas a poder exprimir al máximo tu crawl budget, que es el tiempo que dedica el bot a visitar nuestro sitio.
Del mismo modo, el seo semántico va a mejorar el contexto de la web y, por tanto, a facilitar la comprensión y clasificación del contenido.
Ver Del SEO centrado en Keywords al SEO orientado a temas
En este artículo de Seach Engine Journal, Martin Splitt de Google explica las estrategias de renderizado, su impacto en el SEO y cómo optimizar sitios web para los motores de búsqueda.
2º Clasificación
Aquí se identifican las palabras clave y los demás factores de SEO técnico y On Page: encabezados, title, alt text, etc.
La clasificación de las páginas consiste en identificar el tipo de contenido que tienen y la intención de búsqueda que atienden.
Ver Etiquetas HTML. Importancia para el SEO. Por qué optimizarlas
3º Indexación
Habiendo analizado y clasificado todos los contenidos, estos son indexados a Google para que este los pueda mostrar en las búsquedas según las keywords y la intención de búsqueda para las que han sido catalogados.
El índice es esencialmente una gran base de datos de todas las páginas que el motor de búsqueda ha encontrado y considera lo suficientemente valiosas como para incluirlas en los resultados de búsqueda.
Sin esta última fase, no se podría lograr posicionar en las SERP y conseguir tráfico.
Los motores de búsqueda para asegurarse de que el usuario obtiene los mejores resultados cuando escribe una consulta en la barra de búsqueda ordenan o clasifican resultados de búsqueda del más relevante al menos relevante para una consulta en particular.
Ver Cómo mejorar la experiencia del usuario en nuestra web
Para determinar la relevancia, los motores de búsqueda utilizan algoritmos ( proceso o fórmula mediante el cual se recupera la información almacenada y se ordena de manera significativa). Estos algoritmos han sufrido muchos cambios a lo largo de los años con el fin de mejorar la calidad de los resultados de búsqueda.
Los motores de búsqueda siempre han querido lo mismo: ofrecer respuestas útiles a las preguntas de los usuarios en los formatos más útiles. Cuando los motores de búsqueda apenas empezaban a aprender nuestro idioma, era mucho más fácil engañar al sistema mediante trucos y tácticas que en realidad van en contra de las pautas de calidad.
RankBrain es el componente de aprendizaje automático del algoritmo principal de Google. El aprendizaje automático es un programa informático que mejora continuamente sus predicciones a lo largo del tiempo mediante nuevas observaciones y datos de entrenamiento. En otras palabras, siempre está aprendiendo y, como siempre está aprendiendo, los resultados de búsqueda deberían mejorar constantemente.
Google, por ejemplo, realiza ajustes de algoritmos todos los días: algunas de estas actualizaciones son pequeños retoques de calidad, mientras que otras son actualizaciones generales o básicas del algoritmo implementadas para abordar un problema específico, como el spam de enlaces, la originalidad del contenido, la reputación,etc .
Ver el historial de actualizaciones de Google
Además, Google comenzó a agregar resultados en nuevos formatos en sus páginas de resultados de búsqueda, llamadas funciones SERP . Algunas de estas funciones SERP incluyen:
- Anuncios pagados
- Fragmentos destacados
- La gente también pregunta cajas
- Paquete local (mapa)
- Panel de conocimiento
- Enlaces de sitio
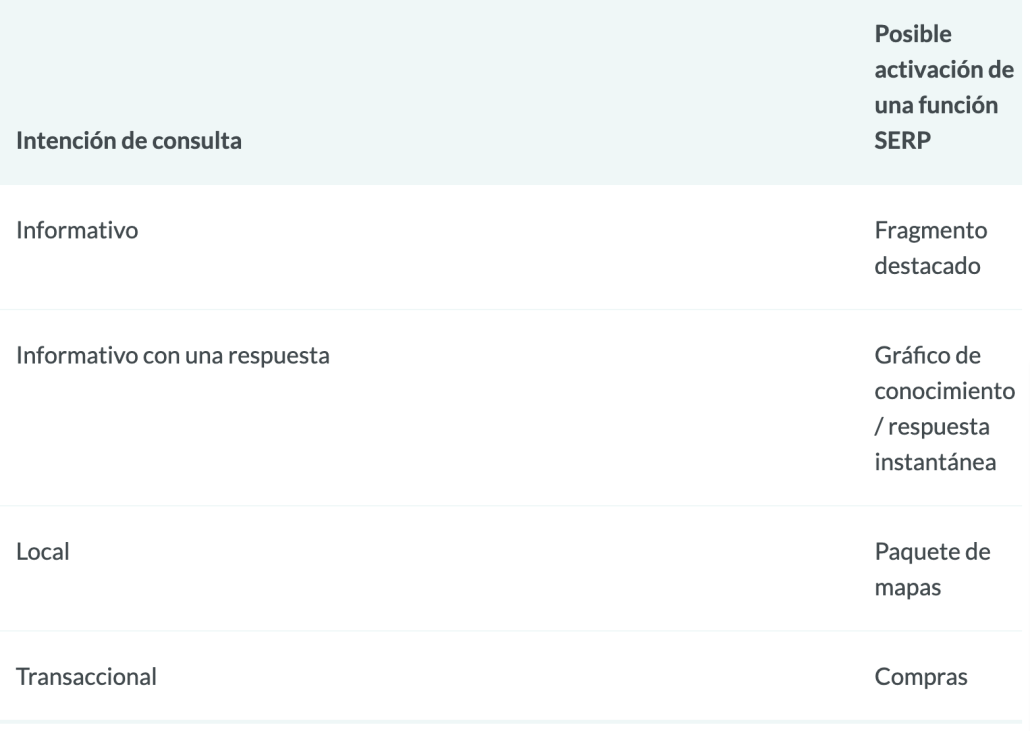
La incorporación de estas funciones provocó cierto pánico inicial por dos razones principales. Por un lado, muchas de estas funciones hicieron que los resultados orgánicos se desplazaran aún más hacia abajo en la SERP. Otra consecuencia es que menos usuarios hacen clic en los resultados orgánicos, ya que se responden más consultas en la propia SERP.
¿Por qué Google haría esto? Todo se debe a la experiencia de búsqueda. El comportamiento del usuario indica que algunas consultas se satisfacen mejor con distintos formatos de contenido.
¿Qué factores pueden afectar negativamente al crawleo de una web?
Como hemos visto, el crawling es un elemento fundamental para el posicionamiento orgánico en buscadores, ya que sin rastreo no hay indexación. Todo lo que le pueda generar problemas al bot y le haga perder tiempo y recursos jugará en nuestra contra para una óptima indexación en los términos que deseamos, como:
- Tiempo elevado de respuesta de nuestro servidor a la hora de acceder a la web
- Velocidad de carga de los recursos que formea parte de la web (fotografía, vídeos, etc.)
- Errores no previstos o no optimizados, como los catalogados de código 400 o 500.
- Enlaces rotos y las redirecciones problemáticas.
- No adaptación a los diferentes formatos (la versión móvil, por ejemplo).
Ver Hosting para SEO: Guía completa + 5 mejores opciones en España en 2026
Errores de navegación comunes que pueden impedir que los rastreadores vean todo el sitio web:
- Tener una navegación móvil que muestre resultados diferentes a los de la navegación de escritorio
- Cualquier tipo de navegación en la que los elementos del menú no estén en el HTML, como las navegaciones habilitadas para JavaScript. Google ha mejorado mucho en el rastreo y la comprensión de Javascript, pero aún no es un proceso perfecto . La forma más segura de garantizar que Google encuentre, comprenda e indexe algo es incluirlo en el HTML.
- La personalización, o mostrar una navegación única a un tipo específico de visitante frente a otros, podría parecer un encubrimiento para un rastreador de motor de búsqueda.
- Olvidar vincular a una página principal de su sitio web a través de su navegación: recuerde, los enlaces son las rutas que siguen los rastreadores hacia las páginas nuevas.
Ver SEO JavaScript. Qué es y cómo afecta al posicionamiento de una web
Qué parámetros utiliza Google a la hora de crawlear una web
Aunque no conocemos las fórmula exacta de sus algoritmos, se sabe que existen más de 200 criterios o variables de Google para posicionar las páginas tras las búsquedas de los usuarios. En este titulado How Search Works se explican algunas cuestiones generales entre las que se encuentran:
- La calidad y actualización de los contenidos
- La ccesibilidad y fluidez de la página
- La estructura del sitio web
- La facilidad de acceso para los rastreadores
- La alidad técnica del sitio web: velocidad de carga, adaptabilidad,…
- La ausencia de errores
Ver Descubierto pero No Indexado: Guía para resolver el error en Google Search Console
Además, existen buenas prácticas que podemos llevar a cabo para optimizarla en función de las variables mencionadas:
- Mejorar la velocidad del sitio: Esto hace que los rastreadores de Google lleguen a más URL internas.
- Enlazado interno: igual que añadimos enlaces externos, darnos relevancia apuntando a landing pages que tenemos optimizadas y eliminar los enlaces rotos que dirigen a páginas eliminadas.
- Arquitectura plana: esto permitirá que el sitio web tenga cierta autoridad y por tanto, atraiga más tráfico.
- Evitar páginas huérfanas: son aquellas que no tienen enlaces internos o externos hacia ningúna otra landing pages.
- No generar contenido duplicado: Google evita invertir su tiempo en indexar páginas iguales o similares, dando preferencia a aquellas con contenido único y de calidad.
En cada update o actualización aprendemos algunos nuevos criterios de Google para posicionar las páginas para las búsquedas de los usuarios mientras vemos como otros desaparecen o pierden importancia.
OJO: La fuga de información sobre la API de Google ha puesto de manifiesto que muchas de las afirmaciones sostenidas por sus responsables no se corresponden con los datos recogidos, pero… estamos g¡hablando de Google y nunca sabremos toda la verdad.
Ver noticia sobre la fuga de información de la API de Google
Cómo facilitar el rastreo SEO de tu web en 2026
La importancia de facilitar el acceso al GoogleBot es máxima.Si pensamos en términos globales hay millones de webs que los bots deben rastrear, por lo que una de sus premisas es discriminar entre aquellas que están optimizadas para SEO y aquellas que no.
Para asegurarte de que los bots de búsqueda puedan rastrear y entender tu sitio web de manera efectiva, es crucial optimizar ciertos aspectos:
- Crea un Sitemap: Un mapa del sitio XML proporciona a los crawlers una guía estructurada de las páginas importantes de tu sitio y súbelo a GSC
- Optimiza la velocidad de la web: Páginas de carga rápida mejoran la experiencia del usuario y permiten que los bots rastreen más contenido en menos tiempo.
- Mejora el enlazado interno: Un buen interlinking facilita la navegación de los crawlers entre las páginas de tu sitio.
- Evita el contenido duplicado: Asegúrate de que cada página tenga contenido único para evitar la penalización de los motores de búsqueda.
- Utiliza Robots.txt: Este archivo permite controlar qué partes de tu sitio pueden ser rastreadas por los bots.
Métricas de compromiso: ¿correlación, causalidad o ambas?
Si bien parece que las métricas de compromiso o interacción nunca han sido una señal de clasificación directa, Google ha sido claro en que definitivamente utilizan datos de clics para modificar el SERP para consultas específicas.
Cuando hablamos de métricas de interacción, nos referimos a los datos que representan cómo los usuarios interactúan con su sitio a partir de los resultados de búsqueda. Esto incluye elementos como:
- Clics (visitas desde la búsqueda)
- Tiempo en la página (cantidad de tiempo que el visitante pasó en una página antes de abandonarla)
- Tasa de rebote (el porcentaje de todas las sesiones del sitio web en las que los usuarios vieron solo una página)
- Pogo-sticking (hacer clic en un resultado orgánico y luego regresar rápidamente a la SERP para elegir otro resultado)
Ver Pogo Sticking. Qué es y cómo afecta al SEO
Dado que Google necesita mantener y mejorar la calidad de la búsqueda, parece inevitable que las métricas de participación sean más que una correlación porque esas métricas se utilizan para mejorar la calidad de la búsqueda, y la clasificación de las URL individuales es solo un subproducto de esto.
“La clasificación en sí misma se ve afectada por los datos de clics. Si descubrimos que, para una consulta en particular, el 80 % de las personas hace clic en el n.° 2 y solo el 10 % en el n.° 1, después de un tiempo nos damos cuenta de que probablemente el n.° 2 sea el que la gente quiere, así que lo cambiamos”.
Udi Manber, exjefe de calidad de búsqueda de Google
Otros conceptos básicos sobre crawling
Crawl Depth
La profundidad de clics o crawl depth sirve para medir la profundidad a la que tienen que llegar los crawlers hasta encontrar un contenido en una web. Esto es muy importante porque sirve como parámetro de la experiencia de usuario, pues referencia la dificultad que tiene el público para dar con lo que busca.
Códigos de respuesta del servidor
Hemos hablado evariaas ocasiones ocasiones que los errores son un problema para el crawleo óptimo de nuestra web. Los códigos de estado del servidor son las respuestas que dan los ordenadores en los que se alojan las páginas web cuando los buscadores piden un contenido anteriormente indexado.
Estos códigos varían en función del estado del contenido y del mismo servidor, se clasifican con diferentes nomenclaturas: 200, 300, 400 y 500. Dentro de cada, hay varias sub-nomenclaturas que identifican estados específicos.
Puedes ir al informe de “Errores de rastreo” de Google Search Console para detectar URL en las que esto podría estar sucediendo; este informe te mostrará errores de servidor (500) y errores de no encontrados (400). Los archivos de registro o Logs del servidor también pueden mostrarte esto, así como una gran cantidad de otra información, como la frecuencia de rastreo,
Antes de poder hacer algo significativo con el informe de error de rastreo, es importante comprender los errores del servidor y los errores «no encontrados».

Los errores 4xx son errores del cliente, lo que significa que la URL solicitada contiene una sintaxis incorrecta o no se puede completar. Uno de los errores 4xx más comunes es el error «404 – no encontrado». Cuando los motores de búsqueda encuentran un 404, no pueden acceder a la URL. Cuando los usuarios encuentran un 404, pueden frustrarse y abandonar el sitio.
Los errores 5xx son errores del servidor, por lo general, ocurren porque se agotó el tiempo de espera de la solicitud de la URL, por lo que Googlebot abandonó la solicitud. Aquí tienes documentación de Google para obtener más información sobre cómo solucionar problemas de conectividad del servidor.
Crawl Budget. Qué es y cómo afecta al SEO
Podemos definir crawl budget o presupuesto de rastreo como el periodo de tiempo que el bot realiza las tres fases del crawling. Google determina en cada caso qué cantidad de tiempo pasa el crawler en cada web.
Para ello tiene en cuenta diferentes factores, como, por ejemplo: la autoridad de dominio, las actualizaciones del contenido y cuán optimizado esté el sitio.
Google no siempre rastreará todo el contenido de una URL ni todas las páginas de una web. De ahí la importancia de aprovechar al máximo la visita del rastreador y que no se vaya sin ver antes las páginas más importantes
El presupuesto de rastreo es más importante en sitios muy grandes con decenas de miles de URL, pero nunca es una mala idea bloquear el acceso de los rastreadores al contenido que definitivamente memos interesante de nuestra web ( páginas de política, páginas de usuarios,…).
El presupuesto de rastreo se divide en dos componentes principales:
- Presupuesto de rastreo asignado (crawl rate): Es la cantidad de recursos que un motor de búsqueda asigna a un sitio web específico. Esto incluye la frecuencia y la velocidad con la que los crawlers visitan y rastrean las páginas de ese sitio web. Si tu web empieza a dar errores 500 o se vuelve lenta, Google baja el ritmo de rastreo.
Es decir, está limitado por la capacidad técnica de tu sitio. - Presupuesto de rastreo consumido (crawl demand): Es la cantidad real de recursos utilizados por el motor de búsqueda al rastrear un sitio web en particular. Esto se determina por factores como el tamaño del sitio web, la estructura de enlaces, la velocidad de respuesta del servidor y la importancia percibida de las páginas dentro del sitio. Depende de si tus contenidos son populares, la frecuencia de publicación si publicas mucho, si has hecho cambios grandes, de la velocidad de carga…
Aquí Google decide si merece la pena gastar recursos contigo o no.
En definitiva, si los crawlers de Google no son capaces de leer una página, éste no conocerá de su existencia o contenidos y será incapaz de incorporarla a su índice. Y no incorporarla al índice implicará no aparecer en las páginas de resultados del buscador y no participar del ranking de posiciones.
Por tanto, el crawling cobra importancia en el posicionamiento orgánico en buscadores en la medida de que es el primer paso para que Google pueda analizar nuestra web y sus diferentes páginas, para posteriormente añadirlas a su índice.
¿En qué parámetros se basa el crawl budget?
La cuestión es que Google no pasa el mismo tiempo rastreando las páginas, sino que les asigna más o menos tiempo de crawl budget en función de diversos factores, entre ellos:
- Autoridad de la página
- Calidad y frecuencia de actualización de los contenidos
- Accesibilidad
- Estructura
- Velocidad de carga
- Fluidez de la navegación
- Ausencia de errores
Qué factores pueden afectar negativamente a nuestro Crawl Budget?
Nuevamente, todos aquellos problemas o limitaciones que hagan gastar más tiempo y recursos al bot de Google pueden afectar a nuestro presupuesto de rastreo, como por ejemplo:
- Un alto tiempo de respuesta del servidor
- Velocidad de carga de recursos excesivos
- Presencia de errores de código 4xx o 5xx
- Páginas aisladas o de difícil acceso
Además, existen otros factores que determinarán el presupuesto de rastreo, como la autoridad de nuestro sitio web.
Cómo mejorar la frecuencia de rastreo
Ahora que ya sabemos que Google asigna un crawl budget a nuestra página, lo que debemos hacer es tratar de aumentar la frecuencia de rastreo. Es evidente que cuanto más presupuesto de rastreo tenga asignado tu sitio web, más tiempo pasará el crawler dentro de él, rastreando sus urls y su contenido.
Existen rastreadores (crawlers) especializados en el análisis y la ponderación de los distintos elementos de la web que influyen en su posicionamiento final: metas, imágenes, arquitectura…
No hay detalle, por mínimo que sea, al que las arañas de Google no sean capaces de llegar. Por eso en el SEO no debemos relajarnos, ni dejar nada al azar ni sin optimizar adecuadamente.
Cómo puedo saber el crawl budget de un sitio web?
Para conocer, y así poder mejorar el presupuesto de rastreo de tu sitio web, tienes que saber cuáles son las URL a las que tiene acceso el bot de Google. La mejor manera de saberlo es analizando y controlando los LOGs que están alojados en el servidor.
El crawl budget te lo tienes que ganar trabajando factores como la autoridad, la velocidad de carga, la frecuencia de publicaciones, la antigüedad de dominio… Todo ello afecta a la hora de asignar presupuesto a tu web.
Sin embargo, el incremento del presupuesto no es directamente proporcional al crecimiento de uuna web.
Puedes ver este video de Screming Frog para ver como analizar los logs de tu servidor.
También puedes ver lo que nos dice Google sobre las Estadísticas de rastreo en este video
¿Qué hacer para mejorar el crawl budget de una web?
Básicamente, tratando de convencer al crawl budget de que nuestra web se merece que los rastreadores le dediquen una parte de su valioso tiempo porque tiene suficiente calidad e interés y es capaz de aportar valor añadido a los usuarios.
Las claves para que los rastreadores de Google visiten con más frecuencia nuestro site son:
- Crear contenido de calidad y, sobre todo, actualizado.
- Mejorar la velocidad de carga de la página. optimiza el código fuente de tu sitio web y utiliza sistemas de caché, tanto a nivel de CMS como a nivel de servidor.
- Cuidar la arquitectura de nuestra página, creando y actualizando con frecuencia un sitemap.
- Corregir errores como los enlaces rotos o inexistentes, contenido pobre,…. Para subsanar estos problemas, que son muy negativos para la experiencia de navegación de los usuarios y penalizados por Google, podemos usar las redirecciones 301 y 302.
- Aumentar el número de enlaces externos, sobre todo si son de páginas de calidad, que apunten hacia nuestra página. De esta forma, mejoraremos el nivel de autoridad de nuestro site y Google considerará que nos debe otorgar más tiempo de rastreo. Parece que ha perdido importancia en el último año y ya no se considera una señal.
- Optimizar el enlazado interno de nuestra página. Para mejorar el crawl depth favoreciendo la navegación del usuario y de los robots para llegar a más páginas y transmitir autoridad a páginas nuevas o que interese posicionar
- Impedir acceso a páginas no interesantes.Para conseguirlo, tenemos que utilizar la etiqueta robots.txt (que indica a los rastreadores las páginas por las que deben pasar) únicamente en aquellas páginas que más nos interesa que sean indexadas por Google y visitadas por los usuarios.
Archivo robots.txt
Los archivos robots.txt se encuentran en el directorio raíz de los sitios web (por ejemplo, sudominio.com/robots.txt) y sugieren qué partes de su sitio deben o no rastrear los motores de búsqueda, así como la velocidad a la que rastrean su sitio, a través de directivas robots.txt específicas .
Utiliza el archivo robots.txt con las etiquetas noindex nofollow para bloquear las páginas que no deseas que sean rastreadas. Por ejemplo, los parámetros de una búsqueda en la web o las paginaciones, que son contenidos poco relevantes con los que los bots solo perderán tiempo.
Cómo trata Googlebot los archivos robots.txt
- Si Googlebot no puede encontrar un archivo robots.txt para un sitio, procede a rastrearlo.
- Si Googlebot encuentra un archivo robots.txt para un sitio, generalmente seguirá las sugerencias y procederá a rastrear el sitio.
- Si Googlebot encuentra un error al intentar acceder al archivo robots.txt de un sitio y no puede determinar si existe o no, no rastreará el sitio.
OJO: algunos hackers utilizan archivos robots.txt para encontrar dónde has ubicado tu contenido privado. Aunque puede parecer lógico bloquear a los rastreadores de páginas privadas, como las páginas de inicio de sesión y administración, para que no aparezcan en el índice, colocar la ubicación de esas URL en un archivo robots.txt de acceso público también significa que las personas con malas intenciones pueden encontrarlas más fácilmente. Es mejor no indexar estas páginas y bloquearlas detrás de un formulario de inicio de sesión en lugar de colocarlas en tu archivo robots.txt.
Ver Por qué deberías dejar rastrear tu web por los boots de IA
Qué pasa con llms.txt. ¿Debo bloquear o no los boots de LLMs como Chat GPT, Claude,….?
El imparable empuje de las plataformas de Inteligencia Artificial ha llenado interent de cientos de boots de distintos LLMs que rastrean internet para entrenar a sus modelos de forma muy agresiva.
Al igual que el archivo robots, este archivo llms.txt es un estándar que permite a los propietarios de sitios web controlar el acceso de los modelos de lenguaje de inteligencia artificial (LLMs) como GPTBot (OpenAI), ClaudeBot (Anthropic), Gemini (Google) o LLaMA (Meta).
Su principal función es ofrecer una vía sencilla y transparente para que los administradores web decidan si sus textos, imágenes o datos pueden ser utilizados en procesos de web crawling, scraping y entrenamiento de modelos de IA generativa.
Aunque Google se muestra reticente a su uso , parece ser que algunos crawlers como GPTBot de OpenAI, ClaudeBot de Anthropic, y los crawlers utilizados por Common Crawl, en un entorno cada vez más automatizado, este archivo llms.txt representa una capa adicional de protección y autonomía digital para los creadores de contenido.
Si permites el acceso a los grandes modelos de lenguaje puedes aumentar la visibilidad de tu marca en entornos de IA conversacional y que tus contenidos sean citados, interpretados o referenciados por herramientas como ChatGPT, Gemini o Claude. Esto puede traducirse en mayor alcance, autoridad y presencia digital en nuevas interfaces de búsqueda.
Por el contrario, bloquear el acceso mediante llms.txt a estos boots es muy importante si quieres proteger tus contenidos, limitar el uso no autorizado de tu contenido, o mantener un mayor control sobre tu propiedad intelectual.
Ver Por qué deberías dejar rastrear tu web por los boots de IA
Sitemaps
Un mapa del sitio es una lista de URL de su sitio que los rastreadores pueden usar para descubrir e indexar su contenido. Una de las formas más sencillas de asegurarse de que Google encuentre sus páginas de mayor prioridad es crear un archivo que cumpla con los estándares de Google y enviarlo a través de Google Search Console.
Si bien enviar un mapa del sitio no reemplaza la necesidad de una buena navegación del sitio, sin duda puede ayudar a los rastreadores a seguir una ruta hacia todas sus páginas importantes.
IMPORTANTE: Proporciona a los boots instrucciones coherentes. Por ejemplo, no incluyas una URL en tu mapa del sitio si la has bloqueado mediante robots.txt o urls que sean duplicadas en lugar de la versión canónica preferida.

¿Pueden desaparecer páginas indexadas en los resultados de Google?
Sí, Google puede eliminar (va a eliminar) páginas de sus índices. Algunas de las principales razones por las que se puede eliminar una URL son:
- La URL está devolviendo un error «no encontrado» (4XX) o un error de servidor (5XX) durante varios rastreos.
- Se agregó una metaetiqueta noindex a la URL para indicarle al motor de búsqueda que omita la página de su índice.
- La URL ha sido penalizada manualmente por violar las Directrices para webmasters del motor de búsqueda y, como resultado, fue eliminada del índice.
- Se ha agregado una contraseña requerida antes de que los visitantes puedan acceder a la página con lo que se ha bloqueado el rastreo de la URL.
Si crees que una página de tu web ya no aparece, puedes utilizar la herramienta de inspección de URL para conocer el estado de la página o utilizar Explorar como Google para enviar URL individuales al índice.
Crawling vs Scraping
En muchas ocasiones se confunden crawling con scraping o vicerversa, pero cada uno se refiere a cosas totalmente distintas y muy específicas.
A grandes rasgos, un scraper también es un rastreador en el sentido de que se dedica a obtener datos de una página web pero su intención es conseguir información de un sitio para utilizarla en otro.
El web scraping se centra en extraer datos de forma automática de una web. La intención del scrapping es crawlear o rastrear un dominio para conseguir información de un sitio para utilizarla en otro, siendo así una técnica muy usada en el Black Hat SEO para copiar páginas web
El crawling se centra extraer la información de páginas web existentes para su indexación y clasificación en buscadores como Google, Bing,….
Qué es el SEO on page y para qué sirve
El SEO on page es un conjunto de técnicas aplicadas en una página web para mejorar su posición en los motores de búsqueda. Se centra en optimizar elementos internos como títulos, meta descripciones, uso de palabras clave, velocidad de carga y la calidad del contenido.
También incluye la mejora de la estructura del sitio y la experiencia de usuario, asegurando así que el sitio no solo atraiga tráfico, sino que también ofrezca una experiencia de navegación eficiente y satisfactoria para los usuarios.
Trabajar el SEO interno es útil en dos sentidos:
- Ayudamos a Google a comprender nuestra web para que su rastreo e indexación sean más sencillos.
- Ofrecemos al usuario una buena experiencia y respondemos a su intencionalidad de búsqueda.
Como ves, es esencial trabajar el SEO on page. Si quieres saber cómo hacerlo, a lo largo de este post te hablaremos de los puntos clave que tienes que trabajar el el processo de optimización SEO on page.
Herramientas de Crawling SEO
Además de los crawlers de motores de búsqueda, existen herramientas especializadas que ayudan a los profesionales de SEO a realizar un rastreo profundo de sus sitios web para identificar errores y oportunidades de optimización. Algunas de estas herramientas incluyen:
- Screaming Frog
- OnCrawl
- DeepCrawl
- Botify
- Netpeak Spider
- Sitebulb
- FandangoSEO
Estas herramientas permiten extraer datos, identificar problemas como enlaces rotos o contenido duplicado, y exportar la información en formatos fáciles de revisar y editar.
Además de extraer los datos, nos permiten exportarlos en formatos cómodos de revisar y editar. Para cualquier SEO, las herramientas de crawling son algo fundamental en su ordenador de trabajo.
Como ves, el crawling es un componente vital del SEO, determinando qué contenido se indexa y cómo se clasifica en los resultados de búsqueda.
Optimizar tu sitio para facilitar el crawling y gestionar eficientemente el crawl budget son pasos esenciales para mejorar tu visibilidad y posicionamiento en los motores de búsqueda.
Con las herramientas adecuadas y las mejores prácticas en mente, puedes asegurarte de que tu sitio web esté bien rastreado e indexado, maximizando así su potencial para atraer tráfico orgánico.
Y tu,¿crees que es importante el crawling de una web para posicionarla correctamente?
En nuestra agencia seo en Barcelona llevamos más de 13 años ayudando a empresas a optimizar sus páginas web y tiendas online para mejorar su posicionamiento, trabajando distintos aspectos de Seo On Page, como el presupuesto de rastreo, la arquitectura web, el contenido de las páginas,… y el Seo Off Page con técnicas de linkbuilding para conseguir enlaces relevantes y de calidad. LLámanos al 653030694 si tienes cualquier duda sobre el SEO de tu página web.
También puedes leer:
Indexación semántica latente: ¿qué es y cómo usarla?
Las claves del SEO para imágenes
7 ideas para mejorar el posicionamiento de tu web
Qué hacer si tu web cae tras una actualización de Google
8 ideas para crear una web optimizada para SEO